# Node.js, # 노드 js, # 크롤링
[패스트 캠퍼스] 한 번에 끝내는 Node.js 웹 프로그래밍 : 프론트엔드 part1(크롤링)
크롤링의 개념을 이해하고 사이트의 크롤링 정책(Robots.txt)을 확인하는 방법
Axios, Cheerio, Puppeteer를 사용한 크롤링 방법
크롤링이란?
크롤링과 웹스크래핑의 개념을 알아보자.
크롤링(crawling)이란? 조직적, 자동화 된 방법(봇:bot)으로 웝드 와이드 웹을 탐색하는 컴퓨터 프로그램
웹 스크래핑(web scraping)이란? 웹 사이트 상에서 원하는 데이터를 추출하여 수집하는 프로그래밍
그렇다면 크롤링은 왜 필요하고 어디에 사용할 수 있을까??

방대한 데이터를 효과적으로 분류하고 내가 원하는 데이터를 추출하여 양질의 정보를 추출하기 위해 사용할 수 있다.
그렇다면 모든 웹 사이트는 어디까지 크롤링을 허용하고 있고 우리는 어떻게 확인할 수 있을까??
답은 바로 robots.txt 파일에 있다.
웹사이트 이름 뒤에 robots.txt를 붙여보자~
https://www.tistory.com/robots.txt
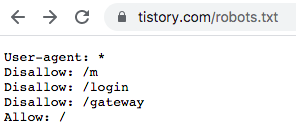
User-agent: *
Disallow: /m
Disallow: /login
Disallow: /gateway
Allow: /
m(모바일), login(로그인), gateway를 제외한 모든 사이트에서 크롤링을 허용한다.
이처럼 우리는 웹 사이트를 크롤링 하기 전 웹 사이트에서 허용하는 크롤링 정책을 확인하여
위법하지 않은 범위에서 크롤링 및 웹 스크래핑을 해야한다.
Axios Cheerio를 활용한 크롤링
크롤링에 사용되는 모듈은 어떤것들이 있을까??
- Axios + Cheerio
- Selenium, beautifulsoap, scrapy
- Puppeteer
Axios를 설치해 보자.
설치하는 방법은 간단하다.
$ npm init
$ npm install axios
$ touch index.js설치가 되었으면 간단한 프로그램을 만들어 보자
const axios = require("axios");
axios.get("http://example.com").then((response) => {
console.log(Object.keys(response));
console.log(response.data);
});axios를 활용하여 example.com의 정보를 가져왔고 data값을 console에 출력해 보았다.
html정보를 가져왔고 내가 필요한 정보만을 구분해서 가져올 수 있는 방법이 없을까?
이러한 기능을 제공해 주는 모듈이 Cheerio다.

$ npm install cheerioCheerio를 활용하여 html을 분류하고 h1의 정보를 출력하는 프로그램을 구현해 보자
const axios = require("axios");
const cheerio = require('cheerio');
axios.get("http://example.com").then((response) => {
const htmlString = response.data;
const $ = cheerio.load(htmlString);
const h1 = $('h1').text(); // H1에 할당될 텍스트 획득
const p = $('p').text(); // P에 할당된 텍스트 획득
const href = $('a').attr('href'); // 하이퍼 링크 정보
console.log(ht);
});
Puppeteer를 활용한 크롤링

Puppeteer를 활용하여 할 수 있는 기능은 어떤것들이 있을까??
- node.js를 통해 크롬 브라우저를 실행
- 사용자가 원하는 뷰포트, 네트워크 환경 등 설정 가능
- 마우스, 키보드, 터치 스크린 등을 코드를 통해 사람이 사용하는 것처럼 구현 가능
- 타임라인 트레이싱, 스크린샷, PDF 다운로드, 확장 프로그램 테스트, 작업 자동화 등 사용 가능
- SPA(Single-Page Application) 크롤링과 pre-rendered content 생성이 가능
puppeteer를 설치해보자
$ npm i puppeteer그리고 웹 페이지를 스크린샷 하여 저장하는 프로그램을 만들어 보자
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();파일의 변화를 감지하여 자동으로 node를 구동시켜주는 nodemon을 설치해 보자
$ npm i -g nodemon크롬 브라우져을 구동하고 화면의 크기를 고정하는 프로그램을 만들어 보자
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
});
const page = await browser.newPage();
await page.setViewport({
width:1440,
height: 1080,
});
await page.goto("https://www.tistory.com/category/life");
const html = await page.content();
})();
마무리
Axios, Cheerio, Puppeteer를 활용한 간단한 크롤링을 만들어 보았다.
Fron-end 개발 경험이 부족하고 TypeScript 용어가 익숙치 않아 강의 문맥이 잘 이해가 안되는 어려움이 있다.
하지만, 따라 구현을 해보고 반복해 들어보고, 블로그를 작성하면서 조금씩 알아가고 있다.
node.js 강의를 들으며 따라하다 보면 자연스럽게 노드 js를 활용한 프로그래밍이 익숙해 지길 기대해 본다.
관련글
'강의 > fastcampus' 카테고리의 다른 글
| [패스트 캠퍼스] 한 번에 끝내는 Node.js 웹 프로그래밍 : 백엔드 part1(Node.js와 개발환경 설정) (0) | 2021.07.05 |
|---|---|
| [패스트 캠퍼스] 풀스택개발자를 위한 한 번에 끝내는 노드JS 웹 프로그래밍 강의 후기 : 프론트엔드 part1(React) (0) | 2021.06.29 |
| [패스트 캠퍼스] 한 번에 끝내는 NODEJS 웹 프로그래밍 강의 후기 : 프론트엔드 part1(크롤링3) (1) | 2021.06.22 |
| [패스트 캠퍼스] 한 번에 끝내는 NODEJS 웹 프로그래밍 강의 후기 : 프론트엔드 part1(크롤링) (0) | 2021.06.16 |
| [패스트 캠퍼스] 블로그 서포터즈 3기 선정(한 번에 끝내는 node.js 웹 프로그래밍) 강의 후기 (0) | 2021.06.02 |



